Using deep learning to get a representative sample of the general population from social media
Wednesday, 05/15/2019
Being able to poll people effortlessly about their attitudes and opinions is of great value to policy makers, social scientists and marketers. However, arriving at meaningful conclusions about society requires the polling data to be representative of the targeted population.
In a new study, University of Michigan School of Information assistant professor David Jurgens and a group of researchers in the United States and Europe present a method to accommodate and adjust for sampling bias in social media data.
Surveys that accurately represent a target population are both costly and infrequent. Social media potentially provides an easy and inexpensive way for people to gather vast amounts of data that contain the feelings and unprompted opinions of users. However, data gathered from social media platforms does not accurately represent offline populations and any conclusions to be drawn are inherently skewed, according to the researchers.
“The big problem is that not everyone uses these online platforms, with some groups of the population using platforms like Twitter more than others,” says Jurgens. “One can’t simply sum up all the posts from a platform where eighty percent of the users are under 35 years old and make a statement about the state of health or political preferences in the whole national population.”
The old methods do not work
The issue of non-representative survey data is nothing particularly new. Researchers have commonly dealt with it through a process called reweighting. This approach counts members of an underrepresented demographic group several times to increase their statistical influence on the aggregated outcome proportional to their group’s share in the target population.
However, the reweighting processes that work online do not work when surveying social media posts. In order to be able to apply these techniques, you have to know the demographics of the audience you are weighting--information that is missing for most social media users.
On social media, only a small percentage of users publicly reveal even the most basic demographic information in their profiles making it very difficult to determine a user’s gender, age and location.
An additional source of noise is the prevalence of organizations, companies and automated “bot” accounts on social media, which are counterproductive to accurate estimates of statistics in human target populations.
Jurgens says all of these issues make it hard to apply correction techniques to social media data.
A new deep learning approach
The research team developed a deep learning model, called M3, which they trained on multiple picture and text datasets, including IMDB, Wikipedia and Twitter.
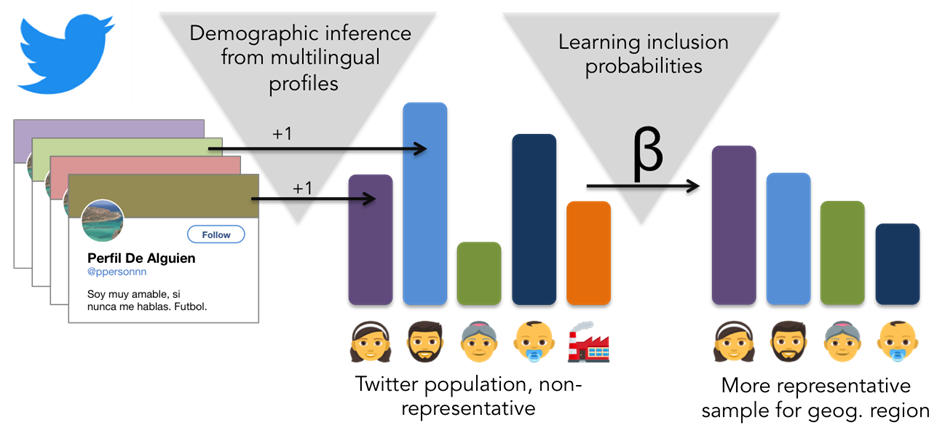
Their methods found success. Using visual clues like profile photos and textual data like usernames, M3 is able to infer age, gender, and organization-vs-human status as attributes of users’ social media profiles more accurately than any existing models.
Previous attempts at classifying social media users used only one of these information types, or modes, and almost all focused almost exclusively on a single language – usually English.
“In contrast, we wanted to develop a system that could really operate in diverse online environments and Europe made for a great case study. Our M3 system is able to predict these attributes in 32 languages by fusing lots of information,” says Jurgens.
These results pave the way for more accurate results from surveying social media posts by laying a foundation of representative population sampling.
The researchers have released an online demo, and their model is available as an easy-to-use Python library under a free license for non-commercial use.
The paper, “Demographic Inference and Representative Population Estimates from Multilingual Social Media Data” will be presented at the 2019 Web Conference.
Authors: Zijian Wang (formerly University of Michigan, now at Stanford University), Scott Hale (University of Oxford and Alan Turing Institute), David Ifeoluwa Adelani (Saarland University), Przemyslaw Grabowicz (University of Massachusetts), Timo Hartmann (GESIS Cologne), Fabian Flöck (GESIS Cologne) and David Jurgens (University of Michigan).
- Jessica Webster, UMSI PR Specialist